- Home
- Pymati - UI for Numerical Computing
- MyBookshelf - web app for ebooks collections
- DDGP - Java Grid Framework
- JALife - A-Life in Java
- Code Analyzer Tool
- Simple Registration Framework
- CS CODEDOM Parser
- Inherited Class Skeleton Generator
- Simple C# Samples
- Python Tools
- Adecaptcha - sounds recognition
- XBMC plugins (for CZ sources)
- Clear_tags - mass ID3 cleaning
- Reverse Template
- mailexp
- Python HTTP Test Set
- Display Switcher
- Simple LDAP Browser
- MP3 Metadata
- Toshtool
- Java Utilities
Contact:
ivan dot zderadicka at seznam dot cz
| If you like stuff here and find it useful, you can show your appreciation also via donation: |
This package contains few tools in python to help to decode audio captchas - or other audio signal representing separated letters. Tools provide :
- Segmentation of audio signal to single letter sounds (now very simple based on signal power level).
- Creation of sound descriptive vector - using MFCC (with big help of numpy, scipy and talkbox library (slightly modified)
- Support for training SVM classifier library libsvm - GUI tool to help with preparing training data and generating training data in correct format
- High level wrapper around SVM classifier and other functions (audio decoding, segmentation, MFCC) to be able to get letters from a mp3 sample
How does it work
- Need to gather enough samples of sounds, manuallly provide transcription to correct letters and create training set
- Train the classifier using it's training tools (easy.py will do all the work).
- Create configuration file which referes classifier model, scaling data and couple of other parameters from training process (especially fixed sound duration for a single letter and relative power level for sound segmentation).
- Use this configuration to recognize letters in other sound samples
Screenshot
GUI tool for creating training sets: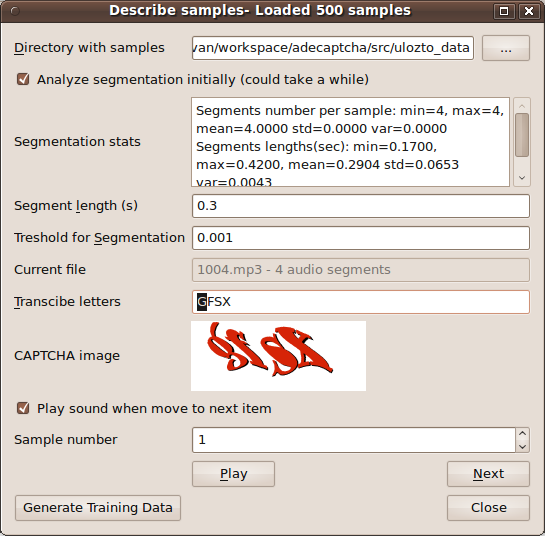
Dependencies
Developed and tested on Ubuntu 9.10 64 bit. Not sure about other platforms. Requires: numpy, scipy, pymad, pyao, pyqt4 - all are available as packages in Ubuntu.Download
Source (including libsvm and talkbox) is available from launchpad here. Contains also some test and training data. SVM library and tools are compiled here for 64bit linux platform. If not right for you, you need to compile libsvm yourself.